
By Gaia-X CTO Pierre Gronlier
Following on the previous Gaia-X Compliance article, today’s article will focus on a term introduced a few months ago in Gaia-X, “Compliance as Code“: what is it, why we need it and how to use it.
Let’s start in January 2000 when Lawrence Lessig published his famous “Code Is Law” article.
Lessig article’s main idea is that the software, which is literally surrounding us today, is constraining our behaviour. The software – or code – then acts as the “law” because it restricts and draws the boundary of what the users can do or not.
Example: a UI without a button or an API without a route to export personal data would lock a user from migrating its data to another service. The service’s developers are “regulating” what the user can do or not.
This paradigm of “code is law” is still true nowadays but slowly shifting towards “law is code” where the regulations define the set of action and draw the boundary of what can and should be done in the digital space.
Examples of such regulations in Europe are, and not limited to, the Digital Service Act, the Digital Market Act, the Data Governance Act, the next Data Act and the future other acts being developed by the European Commission.
The analysis of the regulations is out of scope for this article which, however, will open the discussion of how to operationalise those, especially in the digital space when the regulations are over hundreds of text pages.
The field of Regulatory – Technology (Regtech) already exists for a decade and supports companies to be in conformity with the regulations via the use of technology.
Most of the work done in this area is on the digitalisation of paper-based process and still heavily rely on manual assessment.
The concept of Compliance as Code comes from Infrastructure as Code where the managing and provisioning of infrastructure is done through source code enabling repeatability and reproducibility to enforce consistency instead of tedious manual process.
In addition to the features provided by digitalisation: content integrity verification, signature identification, scaling, … it can leverage all existing tooling used for software development: versioning, release management, testing, …
The second goal of Compliance as Code is to produce digital proofs that are legally relevant and can be assessed by the parties involved in the source code and if needed the judicial authorities of the appropriate jurisdiction.
🧑💻Dev-to-dev: the proofs can be, and not limited to, monitoring or history logs, workload remote attestations, cryptographic signatures for integrity and authentication, like the DKIM-Signature header for emails.
It is important to note that Compliance as Code does not change the rule of law or governance. It remains a tool that does not claim to replace human judgement and expertise.
🧑💻Dev-to-dev: A typical, CAUTION, this machine has no brain, use your own. type of disclaimer is needed to avoid rm -rf /
Descriptive models
Like for Infrastructure as Code solutions which define models for deploying networks, compute instances, storage, load balancer, …, a descriptive model is required for the Compliance as Code.
In Gaia-X context, the main model is defined in the Gaia-X Architecture document.
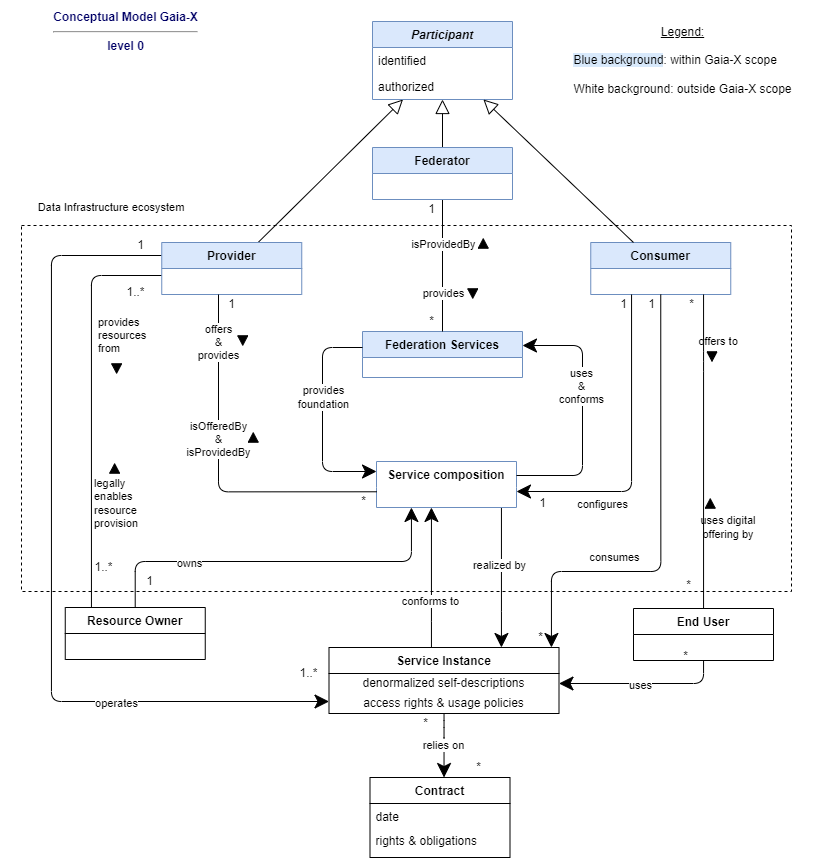
Additional more detailed descriptive models will complement this one and will be covering:
- Service Composition
- Data Exchange
- Identity and Access management
Languages
Given a descriptive model, the next step is to create a language.
Below are two examples of Infrastructure as Code to deploy an OpenStack Virtual Machine instance, one using YAML file formatted for Ansible, one using Terraform language HCL.
Ansible code for a Virtual Machine instance

Terraform code for a Virtual Machine instance
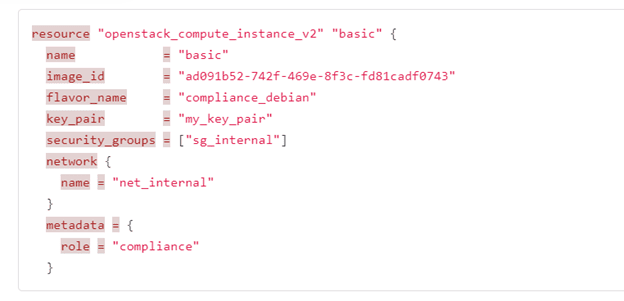
Reading the code above, even if it’s two different languages, it’s possible to identify similarities and patterns because their descriptive models are also similar.
Creating a language for a given domain and objectives is not new: Esperanto, Klingon, Dothraki, Quenya, C++, Haskell, Prolog, Python, … Ha’
For the conciseness of the article, let us focus on the ones relevant to our topic. We need to
- Select the writing system
- Define the syntax or grammar
- Define the semantic fields
The first point can be addressed by using Unicode characters encoded in UTF-8.
The second point is very much linked to Control Structures for conditional, repetitive or sequential flows and variable assignment.
🧑💻Dev-to-dev: if-elseif-else, switch, for, foreach, while, ++i, …
The third point is the interesting one and can be split into sequential steps
- Define controlled vocabulary
- Define taxonomy
- Define ontology
Controlled vocabulary Taxonomy Ontology
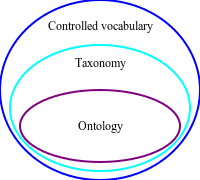
Controlled vocabularies
Given a domain, defining a controlled vocabulary is to come up with a flat list of terms that have a unique unambiguous definition within that domain.
A control vocabulary used by several entities or in Gaia-X context, several ecosystems or dataspaces, enables semantic interoperability by providing a consistent representation of information across documents and records.
Semantic interoperability is here an important notion. It’s the ability to automatically interpret the information exchanged between two or more parties.
Example: One of the Gaia-X Label criteria is for the provider to define the roles and responsibilities of each party in a contract.
This criterion is useful to provide transparency and a high added value would be to enable the comparison of those roles and responsibilities across different contracts. This is possible only if a shared controlled vocabulary for roles and responsibilities is adopted.
Creating a controlled vocabulary requires domain experts and it’s not expected for a controlled vocabulary to always cover all the possible domain scenarios and use cases.
🧑💻Dev-to-dev:
actionsVocab = ["archive", "delete", "display", "extract", "install", "modify", "..."] // from https://www.w3.org/TR/odrl-vocab/
However, controlled vocabularies are basic constructs and don’t offer any type of rule inference nor structured extension. For that, we need a taxonomy.
Taxonomies
A taxonomy is a hierarchically ordered controlled vocabulary.
The simplest example in the Gaia-X descriptive model is the class Participant and its hyponyms LegalParticipant and NaturalParticipant.
🧑💻Dev-to-dev: WARNING, in semantic subclassing from two classes gives you the intersection, not the union of the two.
With this approach, it’s possible to classify and create relations between terms.
Given a Gaia-X defined taxonomy, it’s possible for the ecosystems or dataspaces to easily extend it with their own taxonomy, while keeping a common layer of semantic interoperability.
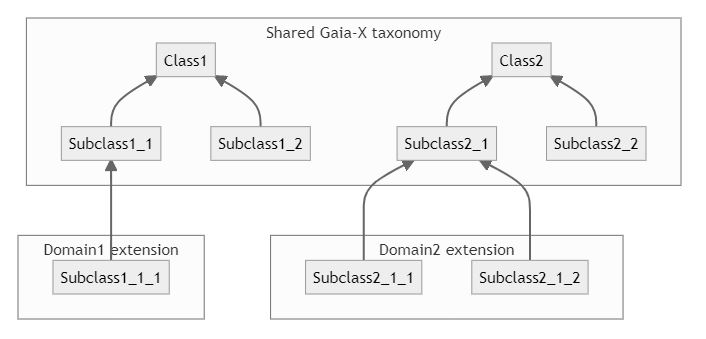
Given one of the main objectives of the Gaia-X association to ease and accelerate data exchange, it is of high importance to address the need of semantic interoperability across ecosystems and dataspaces. This is the reason why several Gaia-X Working Groups are defining taxonomies by identifying the invariants: it enables to measure and compare criteria and compute rules using a common vocabulary.
Warning: the focus here is on the semantic interoperability for the negotiation of the service access or data usage, not about the data being exchanged.
It’s important to note that defining a taxonomy does not define rules. It is still the responsability of the parties involved in the negotiation to come up with their own criteria. The parties operating the engine to compute the rules are accountable for the execution of the negotiation – this will be covered in a future article about the traceability and integrity of a software execution.
Example: two dataspaces using the same taxonomy to negotiate data retention might define different retention periods.
🧑💻Dev-to-dev: a REGO example
default allow := false
allow if {
shortRetention
locatedInEEA
}
shortRetention if input.DataRetention < data.maxDataRetention
locatedInEEA if input.processingLocation.countryCode == data.EEA[_][_]
While the above example gives a glimpse of how negotiation can be improved in terms of transparency and effort, a taxonomy does not capture the domain specific regulations and meaning formulated in natural language. For that, we need an ontology.
Ontologies
An “ontology is a formal, explicit specification of a shared conceptualisation“. (Gruber,1993)
In our case, it means to extract knowledge from texts in natural language and create a model that is understandable by an algorithm so one can automate the rules of the text with a computer.
Building an ontology is significantly more complex than building a taxonomy and for the time being, we limit ourselves to ontology capturing the invariants per domain and by priority relevant for our members.
🧑💻Dev-to-dev: check out a small ontology and a more complex one for a Pizza menu.
The Gaia-X Compliance is an ontology and our first version can be found here.
Also, even if each domain – Service composition, Data Contract, SLA terms, EULA, Privacy Statements, … – might start with distinct ontologies, it is expected that those ontologies will cross-reference each others.
🧑💻Dev-to-dev: using the built-in owl:sameAs property, it’s possible to indicate that two URI refer to the same owl:Thing.
Usage
Going back to the original topic of Compliance as Code, assuming we now have a suitable language, the next step is to write the specification and develop a software stack enabling technical interoperability, ensuring the traceability and integrity of both the exchanged messages and computed results, across ecosystems
Several associations are already working together:
- https://docs.trustrelay.io/elements/dataspaces
- https://docs.x-road.global/
- https://ishareworks.atlassian.net/wiki/spaces/IS/pages/70222165/Technical
- https://github.com/International-Data-Spaces-Association/IDS-RAM_4_0/tree/main/documentation
🧑💻Dev-to-dev: we need to develop the equivalent of the Infrastructure as Code commands below, with immutable logs
$ terraform [plan|apply|destroy]
$ ansible-playbook <playbook.yml>
The next article will cover how Verifiable Credentials are used as the backbone of the Gaia-X Compliance and the importance of the Verifiable Data Registry governance.
In conclusion, Compliance as Code is a mean to consistently produce digital proofs that are legally relevant, using semantic interoperability of a shared ontology and a software stack capable of ensuring traceability and integrity of the rules execution.
Given their respective expertise domain, each Gaia-X Group is expected to contribute to the Gaia-X ontology and provide technical expertise or technical validation. Please liaise back with Cristina.Pauna@gaia-x.eu to support with relevant feedback.
Check out https://docs.gaia-x.eu/framework/ to browse our deliverables.
Qapla’!

